Il modello frontend-backend non è più sufficiente per descrivere i sistemi moderni
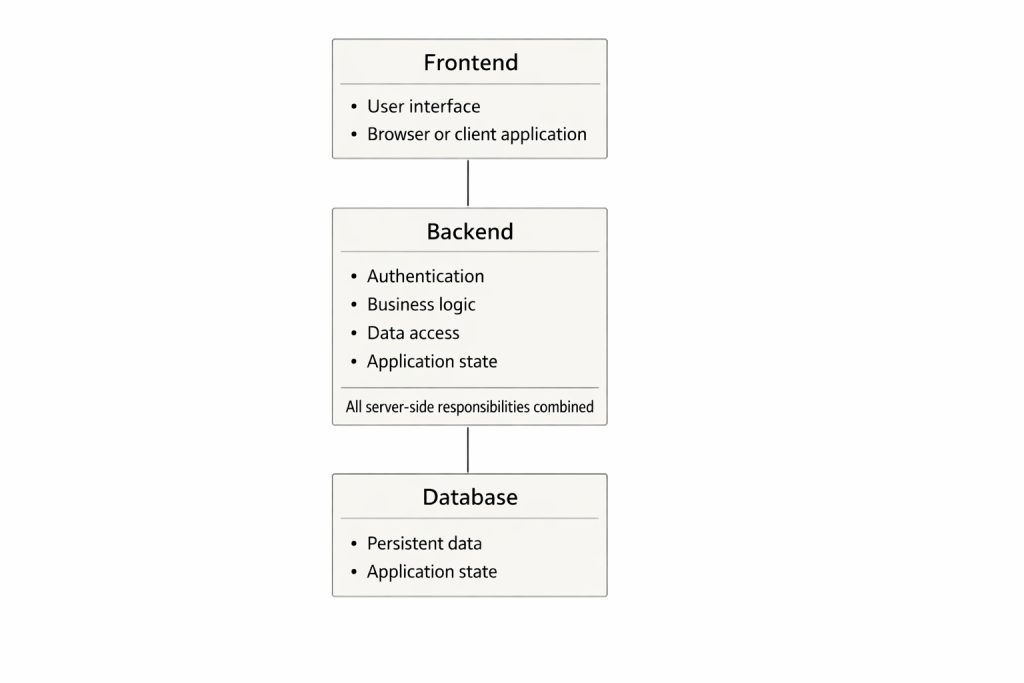
La distinzione tra frontend e backend è stata per decenni uno dei pilastri fondamentali dello sviluppo software. È semplice, facile da insegnare ed efficace dal punto di vista pedagogico, ed è per questo che continua a essere ampiamente utilizzata nelle università e nei programmi di formazione. L’interfaccia utente si trova davanti, il server dietro e il database ancora più in profondità. L’utente invia una richiesta, il backend la elabora e restituisce una risposta. Il modello è logico e intuitivo, ma allo stesso tempo sempre più distante dalla realtà in cui operano i sistemi moderni.
Questo non significa che il pensiero frontend-backend sia stato sbagliato. Al contrario, è stato un’astrazione storicamente necessaria. Il problema emerge quando diventa il punto di arrivo del ragionamento, anziché il suo punto di partenza. Man mano che i sistemi crescono, il numero di utenti si moltiplica e le richieste in termini di prestazioni, disponibilità e sicurezza diventano più stringenti, un modello a due blocchi non è più sufficiente a descrivere la struttura reale di un sistema, e ancor meno la reale distribuzione delle responsabilità.
Origini storiche e limiti del modello
Il modello frontend-backend originario nasce in un’epoca in cui le applicazioni erano spesso monolitiche. Un singolo processo server conteneva autenticazione, logica di business, gestione dello stato e accesso al database. L’interfaccia utente costituiva uno strato sottile sopra questo nucleo. Tutte le responsabilità lato server erano concentrate in un’unica entità, e per lungo tempo questa soluzione ha funzionato egregiamente.
In quel contesto, le prestazioni venivano migliorate principalmente tramite scalabilità verticale: più memoria, processori più veloci, sistemi di storage più performanti. Scalare significava utilizzare macchine più grandi. La sicurezza era in gran parte demandata alla logica applicativa e la gestione del traffico avveniva spesso in profondità all’interno dell’applicazione stessa. Questo modello è tuttora valido per sistemi piccoli e casi d’uso semplici, e non va sottovalutato.
Proprio per questo, tuttavia, diventa pericoloso come base didattica se vi si rimane ancorati troppo a lungo. Trasmette l’idea di un sistema come di un unico condotto lineare, in cui tutto avviene in sequenza e ogni richiesta attraversa l’intera catena, indipendentemente dal fatto che ciò sia necessario o sensato.
L’evoluzione del pensiero north-south
Il modello frontend-backend tradizionale si basa quasi esclusivamente sul traffico north-south. La richiesta dell’utente scende attraverso il sistema, viene elaborata e la risposta risale. Questo modo di pensare era naturale in un’epoca in cui i sistemi erano semplici e la comunicazione interna limitata.
Con la crescente distribuzione dei sistemi e l’aumento della loro complessità, è emersa la necessità di separare il traffico esterno da quello interno. I servizi hanno iniziato a comunicare tra loro, i dati sono stati sincronizzati in background e il coordinamento interno è diventato una parte significativa del carico complessivo. A questo punto, il traffico east-west ha assunto un’importanza pari a quella del traffico tradizionale orientato all’utente.
Non si è trattato solo di un cambiamento tecnico, ma di un cambiamento di mentalità. Il sistema non era più un semplice condotto, ma un ecosistema. Non tutto il traffico aveva lo stesso valore e non tutto doveva percorrere lo stesso percorso.
Una trasformazione architetturale
Quando il traffico north-south e quello east-west vengono distinti, la struttura del sistema cambia in modo sostanziale. L’architettura non si organizza più attorno a un unico componente centrale, ma inizia a stratificarsi naturalmente in base alle responsabilità. Il traffico esterno può essere ricevuto, interpretato e, se necessario, limitato già ai margini del sistema, prima di gravare sulla logica applicativa o sui dati persistenti. Allo stesso tempo, il traffico interno può essere ottimizzato secondo criteri differenti: affidabilità, coerenza e osservabilità diventano prioritari.
Questo cambiamento non è solo tecnico, ma anche concettuale. Quando un sistema viene inteso come l’interazione di più flussi di traffico, non ha più bisogno di presentarsi come un unico “backend” omogeneo. Ne emerge un modello multilivello, in cui ogni livello ha un ruolo chiaro e una responsabilità ben delimitata. Nessun livello cerca di risolvere l’intero problema; ciascuno affronta solo la propria parte. Questo riduce l’accoppiamento interno e rende il sistema più comprensibile, non come una singola scatola, ma come un insieme strutturato.
Dal punto di vista dell’utente, questo cambiamento è spesso impercettibile. L’utente non interagisce più con “il backend”, ma con più livelli del sistema, anche se ciò non si riflette nell’interfaccia. La richiesta avanza passo dopo passo, e ogni livello prende una decisione autonoma sul fatto che la richiesta debba proseguire. In questo senso, il sistema inizia ad assomigliare più a un processo deliberativo che a un flusso lineare.
Questa capacità di valutazione è il cuore del modello multilivello. Ogni livello svolge meno compiti rispetto a un backend tradizionale, ma li esegue in modo più consapevole e controllato. Le responsabilità non scompaiono; si spostano verso i punti in cui possono essere esercitate in modo più efficace. L’architettura non diventa complessa perché si aggiungono strati arbitrari, ma perché la realtà stessa è complessa. La stratificazione è un modo per rendere questa complessità visibile e, quindi, governabile.
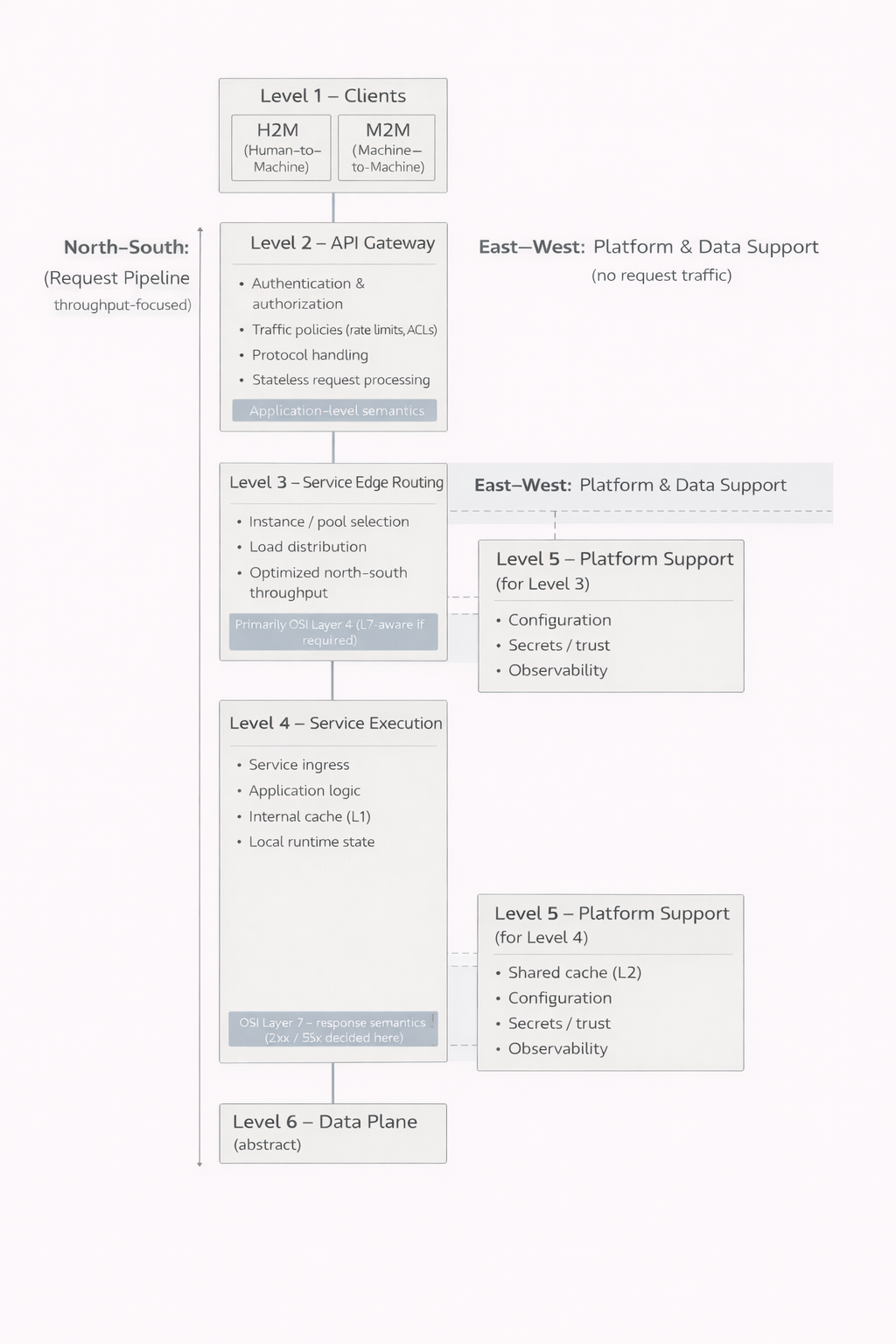
I livelli 1-6 come insieme
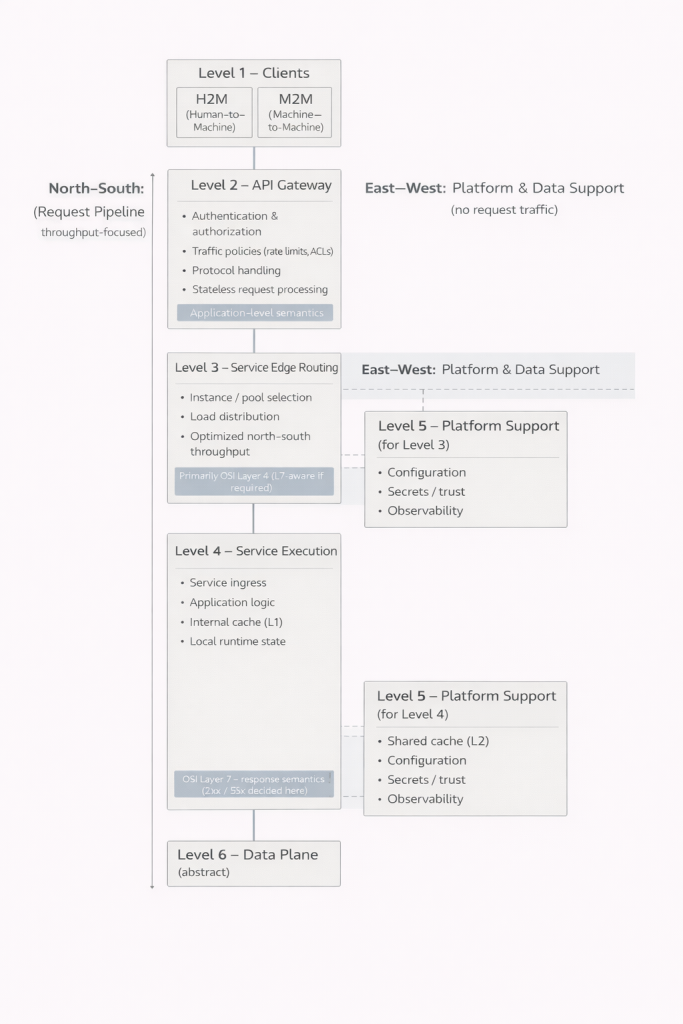
Il primo livello è costituito dai client. Le interfacce utilizzate dagli esseri umani e le integrazioni tra macchine possono apparire simili dall’esterno, ma i loro requisiti e comportamenti possono essere profondamente diversi. Riconoscere questa distinzione è fondamentale, poiché il sistema deve essere in grado di servire entrambi in modo controllato.
Il secondo livello rappresenta il confine tra il sistema e il mondo esterno. Qui avvengono l’autenticazione, l’autorizzazione, la limitazione del traffico e spesso anche la gestione dei protocolli. Un aspetto cruciale è che non tutte le richieste superano questo livello. Credenziali non valide, permessi insufficienti o limiti superati possono essere respinti immediatamente. Questo riduce il carico sui livelli più profondi del sistema e migliora sia le prestazioni sia la sicurezza.
Il terzo livello è responsabile dell’instradamento del traffico verso i servizi appropriati. Nei sistemi piccoli, questo livello può essere integrato nel successivo e non sempre viene riconosciuto come entità distinta. Quando il numero di utenti e di istanze cresce, tuttavia, diventa indispensabile. Consente la distribuzione del carico, l’isolamento dei guasti e una scalabilità controllata.
Il quarto livello è quello in cui si svolge il lavoro effettivo dell’applicazione. Qui risiedono la logica di business, la costruzione delle risposte e la gestione dello stato locale. È importante comprendere che questo livello non è necessariamente un unico blocco. Può essere composto da più componenti paralleli che servono lo stesso obiettivo. Ciò permette di aggiornare o dismettere singole parti senza interrompere l’intero servizio. L’utente potrebbe non accorgersi di nulla, anche mentre avvengono cambiamenti significativi all’interno del sistema.
Il quinto livello introduce il controllo operativo. Configurazioni, relazioni di fiducia, segreti e osservabilità non fanno parte della logica applicativa, ma sono essenziali per un funzionamento sicuro e affidabile. Nei sistemi piccoli, queste responsabilità sono spesso nascoste e integrate in altri componenti. Con la crescita del sistema, emergono inevitabilmente come temi distinti.
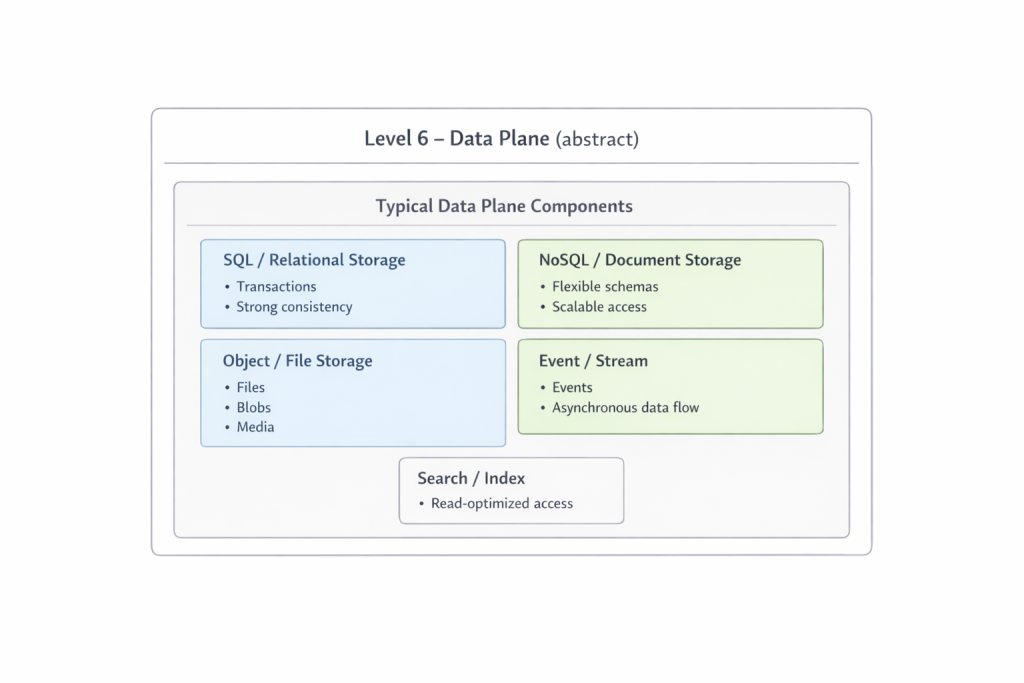
Il sesto livello è il dominio dei dati. È volutamente mantenuto astratto, poiché merita un’analisi a sé stante. File, relazioni, eventi e flussi costituiscono la base su cui poggia tutto il resto. Più una richiesta si addentra in questo livello, più tende a diventare costosa e lenta. Proprio per questo, la capacità dei livelli precedenti di fornire risposte in anticipo rappresenta un vantaggio così rilevante.
Prestazioni e scalabilità
Forse il beneficio più sottovalutato di questo modello è che non tutto deve essere eseguito sempre. Nel pensiero frontend-backend tradizionale, una richiesta percorre spesso gran parte del sistema prima che venga anche solo presa in considerazione l’idea di respingerla. Nel nuovo modello, ogni livello agisce come un filtro intenzionale che valuta se abbia senso inoltrare la richiesta allo stadio successivo. Non si tratta solo di ottimizzazione delle prestazioni, ma di una proprietà strutturale che cambia radicalmente il comportamento del sistema sotto carico.
Già ai margini del sistema è possibile prendere decisioni che interrompono immediatamente una richiesta. Autenticazione, autorizzazione e limitazione del traffico non sono più preoccupazioni interne all’applicazione, ma passaggi preliminari prima di consumare qualsiasi risorsa della logica applicativa. In pratica, ciò significa che richieste non valide, non autorizzate o abusive non raggiungono mai le parti più costose del sistema.
I meccanismi di caching rafforzano ulteriormente questo principio. Quando una risposta può essere servita direttamente da uno strato periferico o di servizio senza accedere ai dati persistenti, si risparmiano tempo e capacità complessiva del sistema. Non è solo una questione di velocità, ma anche di stabilità: quanto meno si ricorre alle risorse più lente e costose, tanto meglio il sistema resiste a picchi di carico e situazioni eccezionali.
La scalabilità, in questo modello, non è più unidimensionale. Il sistema può essere ampliato e rafforzato in modi diversi a livelli diversi. Lo strato periferico può essere scalato per gestire volumi di richieste maggiori senza modificare la logica applicativa. Il livello di servizio può essere esteso tramite componenti paralleli che condividono il carico e consentono aggiornamenti controllati. Il livello dei dati può essere ottimizzato separatamente, senza incidere direttamente sul traffico degli utenti.
Questa scalabilità multidirezionale riduce la necessità di componenti singoli sovradimensionati. Invece di un backend unico che cresce senza controllo, responsabilità e carico si distribuiscono in modo naturale. Il risultato è un sistema che non solo scala meglio, ma si comporta anche in modo più prevedibile man mano che il carico aumenta.
Responsabilità e sicurezza
Quando le responsabilità sono chiaramente separate, la sicurezza diventa una proprietà intrinseca dell’architettura. Nel modello tradizionale, la sicurezza è spesso trattata come una caratteristica dell’applicazione: i controlli vengono eseguiti dove la richiesta viene infine elaborata. Ciò consente a traffico malevolo o errato di penetrare profondamente nel sistema prima di essere bloccato.
Nel modello multilivello, questa dinamica si ribalta. Il traffico dannoso viene identificato e bloccato il prima possibile. Lo strato periferico non è solo un guardiano, ma una linea di difesa attiva che protegge i livelli interni. Questo riduce il carico sulla logica applicativa e diminuisce il rischio che un singolo errore o una vulnerabilità si trasformi in un problema diffuso.
L’approccio Zero Trust si inserisce naturalmente in questa architettura. Non è un’aggiunta né una scelta ideologica, ma la conseguenza logica di un sistema in cui nessun livello si fida implicitamente di un altro. Ogni richiesta viene valutata nel suo contesto e i permessi vengono verificati dove hanno il maggiore impatto. Il sistema diventa così più resiliente sia agli attacchi esterni sia ai guasti interni.
La chiarezza delle responsabilità aiuta anche a livello organizzativo. Quando è chiaro quale team è responsabile di quale livello, i problemi possono essere individuati e risolti più rapidamente. La sicurezza non rimane una responsabilità vaga e condivisa, ma si ancora a strutture e ruoli concreti.
Debolezze e realtà operative
È importante affermarlo con chiarezza: le architetture multilivello non sono prive di difficoltà. Introducono più elementi in movimento, nuove interfacce e una maggiore esigenza di comprendere il sistema nel suo insieme. Configurazioni errate, confini mal definiti o responsabilità poco chiare possono creare situazioni in cui i problemi sono più difficili da individuare rispetto a modelli più semplici.
Le decisioni prese in anticipo comportano inevitabilmente scelte basate su un contesto limitato. Una limitazione del traffico troppo aggressiva o una cache configurata in modo scorretto può bloccare traffico legittimo o fornire dati errati. Questi rischi sono reali e non vanno minimizzati.
La differenza rispetto al modello tradizionale non sta nel fatto che i problemi scompaiano, ma nel luogo e nel modo in cui si manifestano. Nei sistemi multilivello, i problemi sono spesso più visibili e meglio circoscritti. Possono essere ricondotti a un livello specifico e risolti senza dover fermare o riavviare l’intero sistema. Nel lungo periodo, ciò rende il sistema più gestibile, nonostante la sua complessità strutturale.
Conclusione
Il modello frontend-backend non è sbagliato, ma è insufficiente per descrivere la realtà dei sistemi moderni. È un ottimo punto di partenza, ma un pessimo punto di arrivo. Analizzando i sistemi in termini di livelli e responsabilità, emerge una comprensione più profonda e realistica di come si ottengano realmente prestazioni, sicurezza e scalabilità.
Il frontend-backend non è superato perché abbia fallito, ma perché ha avuto successo. Ha svolto il suo ruolo come tappa necessaria nell’evoluzione dell’architettura software. Oggi, di fronte a sistemi più complessi e a requisiti più elevati, è tempo di passare a una nuova astrazione, una che non tema la complessità della realtà, ma la renda gestibile.
Una delle conseguenze più scomode di questo modello è che esso rompe anche concettualmente la separazione tradizionale tra frontend e backend. Quando il codice frontend viene distribuito dal server, non è un’eccezione architetturale, ma parte dello stesso flusso di traffico di qualsiasi altra risorsa. Attraversa la stessa pipeline di richieste, è soggetto agli stessi meccanismi di autenticazione, caching e controllo del traffico, ed è esposto alle stesse decisioni di sicurezza e di prestazioni di ogni altra risposta. In questo senso, il frontend non è un livello separato, ma uno dei tanti artefatti prodotti dal server.
Questa visione genera spesso resistenza proprio perché rende visibile ciò che prima poteva essere ignorato. Quando il frontend è trattato come parte dello stesso flusso, il suo impatto su prestazioni e sicurezza diventa inevitabile. La distribuzione di codice statico non è una nota marginale priva di costi, ma un’operazione che genera carico e che può essere gestita in modo efficiente ai margini del sistema o, al contrario, consumare inutilmente risorse della logica applicativa. Allo stesso tempo, la distribuzione del frontend diventa una questione di sicurezza: codice versionato in modo errato, memorizzato male in cache o eccessivamente esposto rappresenta un rischio tanto reale quanto una risposta backend difettosa.
Nel nuovo modello, questo non è un problema, ma l’obiettivo. Integrando il frontend nella stessa struttura delle altre risposte, esso beneficia degli stessi meccanismi di protezione e ottimizzazione. Il traffico malevolo o errato può essere bloccato prima di raggiungere la logica applicativa, e le richieste ripetute possono essere soddisfatte senza toccare i componenti più costosi del sistema. Il frontend non perde il suo ruolo di interfaccia utente, ma perde la sua immunità architetturale – ed è proprio questo che rende il sistema più veloce, più sicuro e più onesto da descrivere.
Il modello presentato in questo articolo è volutamente mantenuto a un livello generale e concettuale. Il suo obiettivo non è ancora quello di prescrivere un’implementazione specifica, ma di cambiare il modo stesso in cui i sistemi vengono concepiti. Ogni livello descritto porta con sé responsabilità, rischi e opportunità proprie, e comprenderli richiede più di un’analisi superficiale. Per questo motivo, negli articoli successivi questi livelli verranno esaminati uno per uno, con calma e separatamente, per approfondirne ruoli, limiti e implicazioni pratiche.
In quei testi futuri, il modello concettuale sarà ancorato anche a esempi più concreti. Codice, container e semplici schemi di implementazione verranno utilizzati per illustrare come gli stessi principi si manifestino nella pratica, senza spostare l’attenzione su tecnologie specifiche. L’obiettivo non è fornire una ricetta pronta, ma mostrare come le decisioni architetturali si riflettano in sistemi reali.
In particolare, il sesto livello, la cosiddetta Data Plane, è stato volutamente lasciato qui in forma astratta. Non si tratta di un dettaglio marginale, ma di un ambito che richiede uno spazio e un quadro concettuale propri. Nei prossimi articoli verrà analizzato come questo insieme possa essere strutturato tecnicamente in un sistema coerente, senza costringere l’organizzazione a diventare un unico monolite. Coerenza strutturale e decentralizzazione organizzativa non sono opposte, ma rappresentano una tensione centrale dell’architettura moderna. Comprendere questa tensione è il prerequisito per trasformare questo modello, da semplice schema, in un sistema realmente funzionante.